はじめに
YoctoProjectはToasterというWebインターフェースを提供している。
Toasterを使うとコマンドラインに慣れていないユーザーでもYoctoProjectを使用して
ビルドを行うことができ、ビルドされたイメージをブラウザでダウンロードすることもできる。
筆者はコマンドラインのほうが色々ラクなのでなのでこれまで使ってこなかったがせっかくなので調べてみる。
Toasterの機能
マニュアルの説明
Toaster ManualによるとToaster機能は下記の通り。
- Browse layers listed in the various layer sources that are available in your project (e.g. the OpenEmbedded Layer Index at https://layers.openembedded.org/).
- Browse images, recipes, and machines provided by those layers.
- Import your own layers for building.
- Add and remove layers from your configuration.
- Set configuration variables.
- Select a target or multiple targets to build.
- Start your builds.
あと
- See what was built (recipes and packages) and what packages were installed into your final image.
- Browse the directory structure of your image.
- See the value of all variables in your build configuration, and which files set each value.
- Examine error, warning, and trace messages to aid in debugging.
- See information about the BitBake tasks executed and reused during your build, including those that used shared state.
- See dependency relationships between recipes, packages, and tasks.
- See performance information such as build time, task time, CPU usage, and disk I/O.
ざっくりと要約
ブラウザで以下のことができる。
- LayerIndex上のレイヤ、レシピの検索ができる
- 見つかったレイヤ、レシピを自分のプロジェクトに追加、削除ができる
- local.conf(実際にはtoaster.conf)に変数の設定ができる
- ビルドができ、ビルド結果をダウンロードできる
- ビルド時の情報(実行されたタスクや収録されたレシピ、パッケージの一覧、rootfsのディレクトリツリーなど)が閲覧できる
- ビルド時のリソースのログ(ビルド時間、CPU使用率、ディスクIOなど)が閲覧できる
その他
個人的にキーとなるポイントは下記。
- LayerIndexと連携している
- ビルド結果などのデータをsqliteのデータベースに保存している
Toasterの実行
とりあえずToasterを一度使ってみる
環境構築
Pokyの取得
下記を実行しPokyを取得する。
$ mkdir -p ~/yocto/toaster
$ cd ~/yocto/toaster
$ git clone git://git.yoctoproject.org/poky.git -b kirkstone
依存するpythonパッケージのインストール
ToasterはPython3のDjangoを使用しているため下記のように必要なパッケージをインストールする。
$ sudo apt install -y python3-pip
$ pip3 install --user -r poky/bitbake/toaster-requirements.txt
Toasterの起動
いつもどおりbitbakeの環境変数を読み込む
$ source poky/oe-init-build-env
下記でToasterを起動する。
$ source toaster start webport=0.0.0.0:8400
筆者の環境ではbitbakeを実行するPCとブラウザなどで作業するPCが異なっているため
リモートアクセスできるように「webport=0.0.0.0:8400」を指定している。
これによって下記のようにアクセスすることができる。
http://”IPアドレス”:8400
core-image-minimalをビルド
とりあえず、qemuarm64向けのcore-image-minimalをビルドしてみる。
ブラウザ起動後の手順は下記のようになる。
- プロジェクトの作成
- MACHINEの設定
- イメージレシピのビルド
プロジェクトの作成
ブラウザでToasterにアクセスすると下記のようになる。
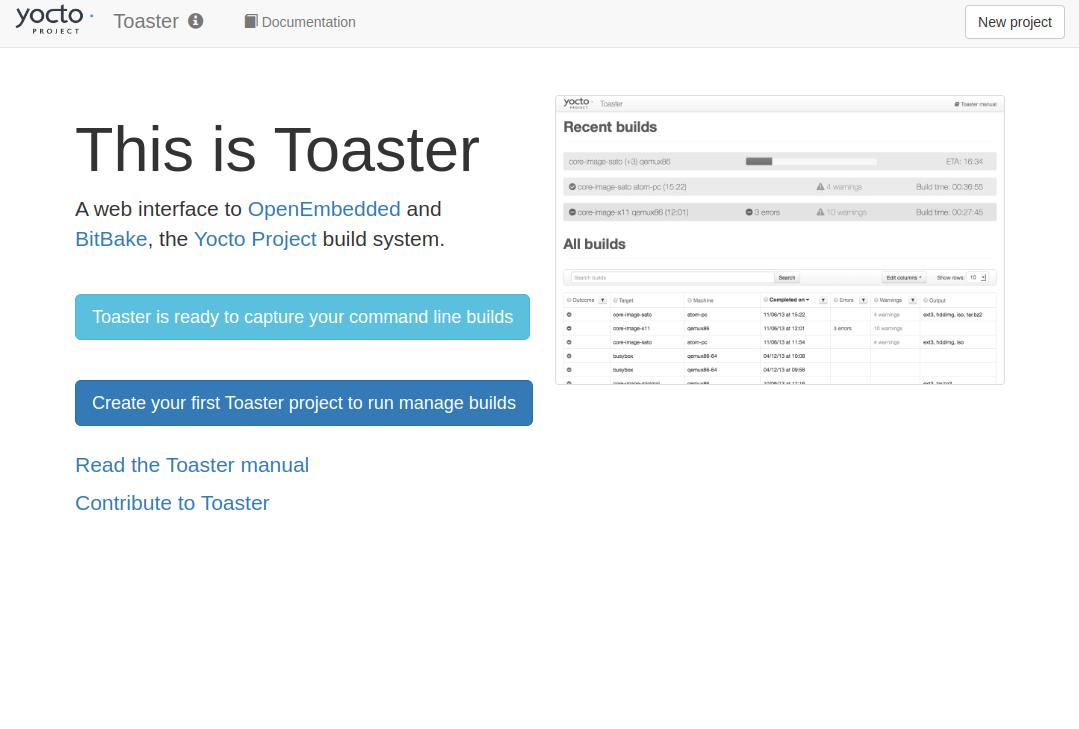
「Create your first Toaster project to run manage builds」か、画面右上の「New project」をクリックし、プロジェクト作成画面に遷移する。
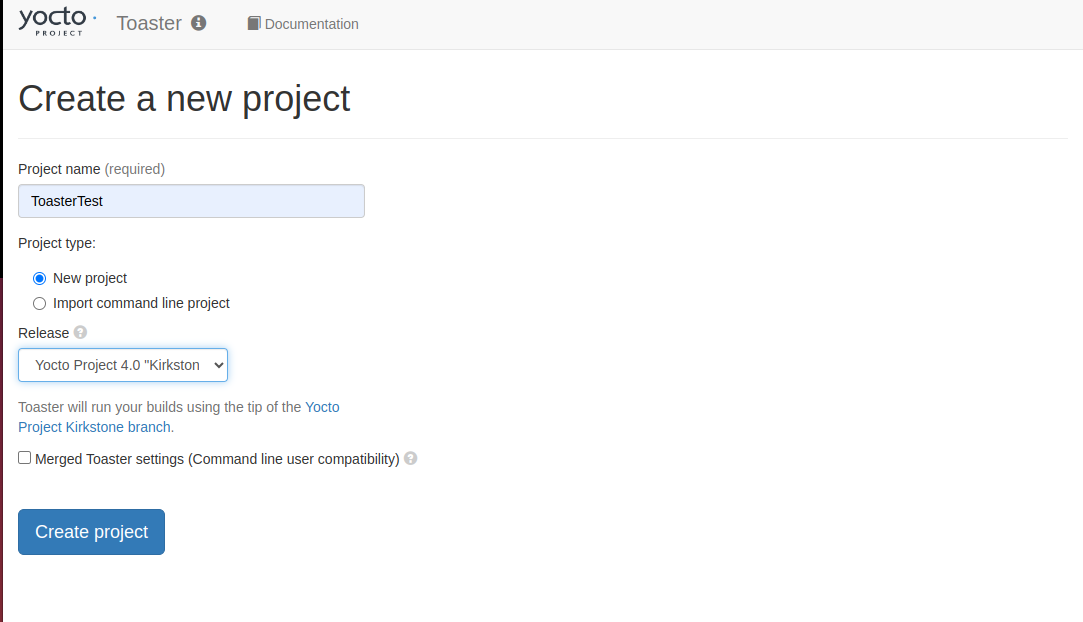
下記を設定する
- 「Project Name」に
ToasterTestと入力
- 「Release」で
Yocto Project 4.0 "Kirkstone"を選択
- 「Create project」をクリック
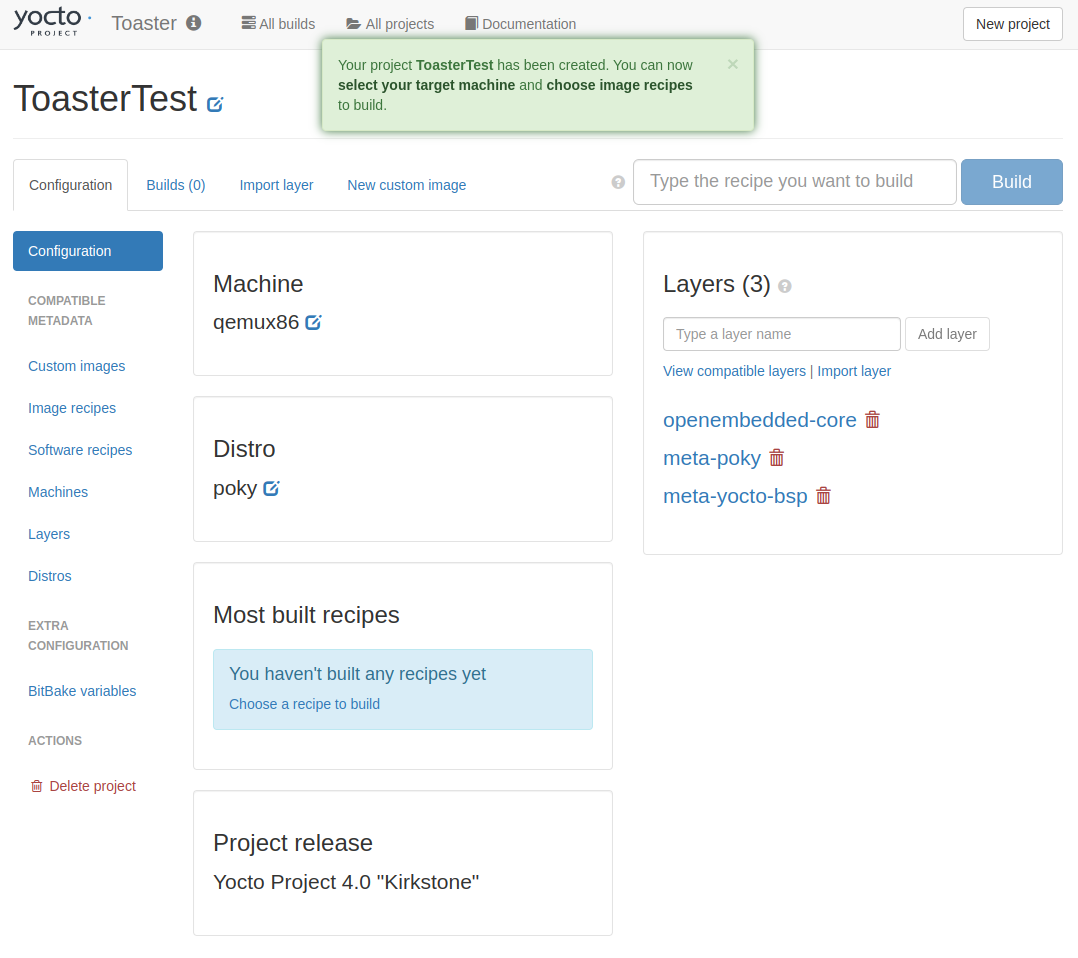
プロジェクトが作成され、Configuration画面に遷移する。
MACHINEの設定
初期設定ではqemux86になっているので、qemuarm64に変更する。

Machineのボックスのリンクをクリックし、MACHINE変更に遷移。

エディットにqemuarm64を入力し、「Save」をクリック。

MACHINEが変更された。
イメージレシピのビルド
イメージレシピを選択する。
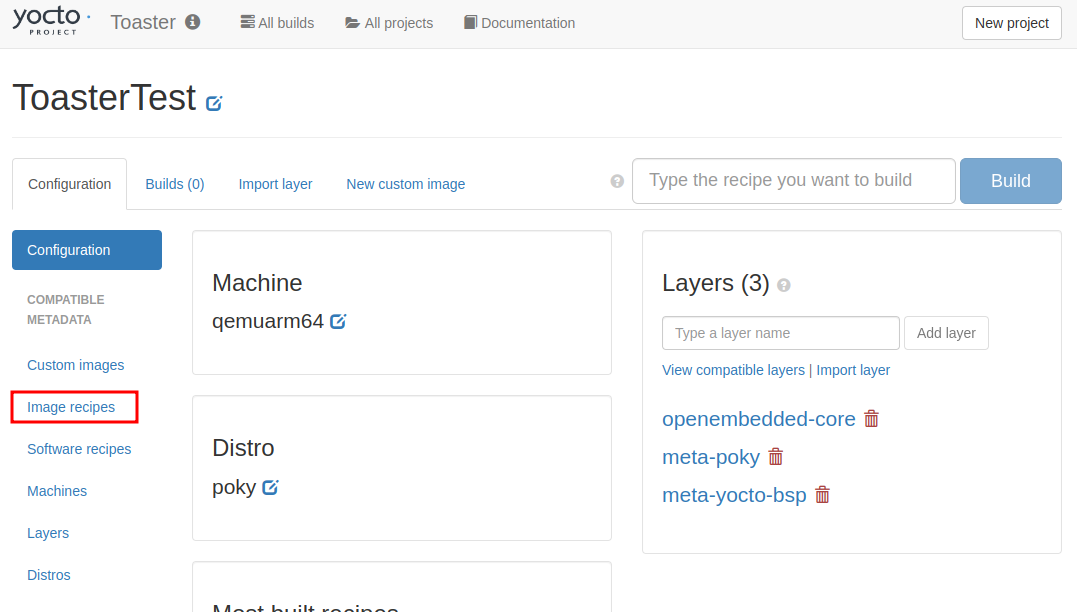
画面左側の「Image recipes」をクリックしImage recipes画面に遷移する。
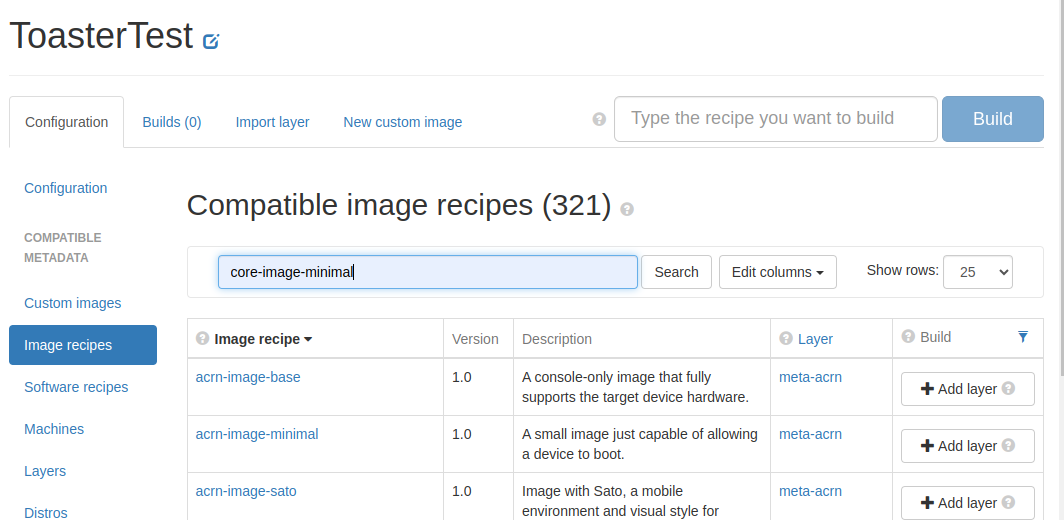
下記を行う。
- エディットに
core-image-minimalと入力
- 「Search」をクリック
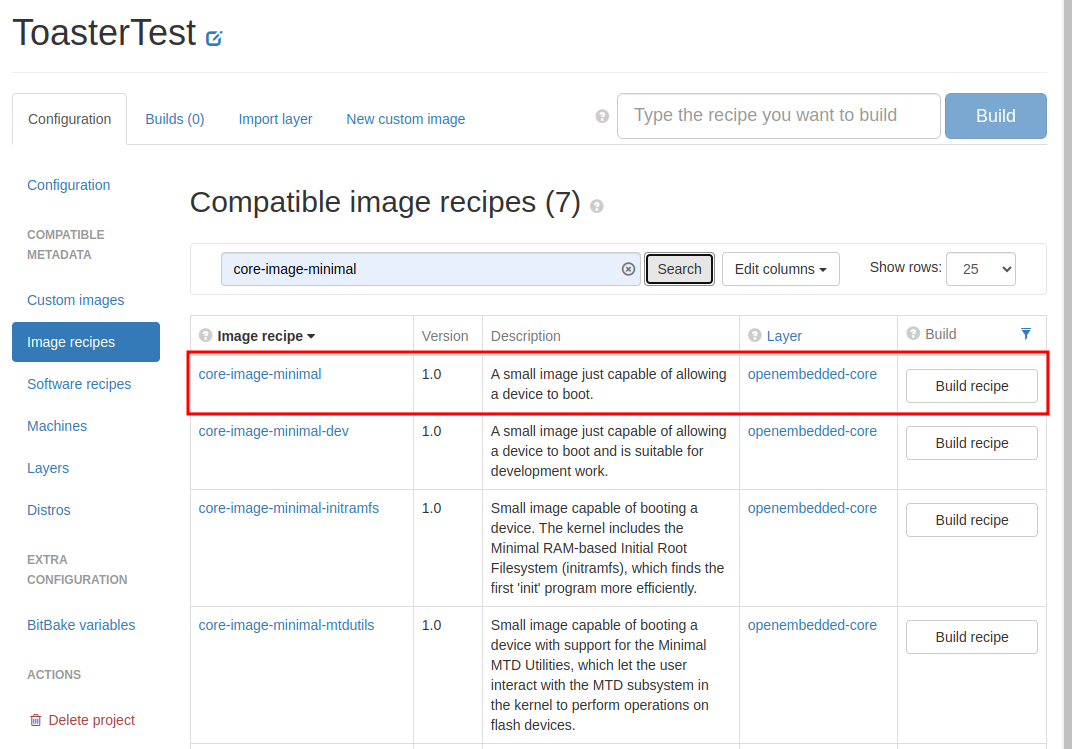
検索結果に「core-image-minimal」が出てくるので、画面右側の「Build recipe」をクリック。

ビルドの進捗が表示される。

ビルドが完了すると、ビルド履歴の画面に遷移する。
この時点でビルドしたものの履歴や、ビルド完了時刻、ビルドにかかった時間などの情報が得られる。
エラーや警告なども見ることができる。

完了したビルドのリンクをクリックするとビルドの詳細な情報を見ることができる。
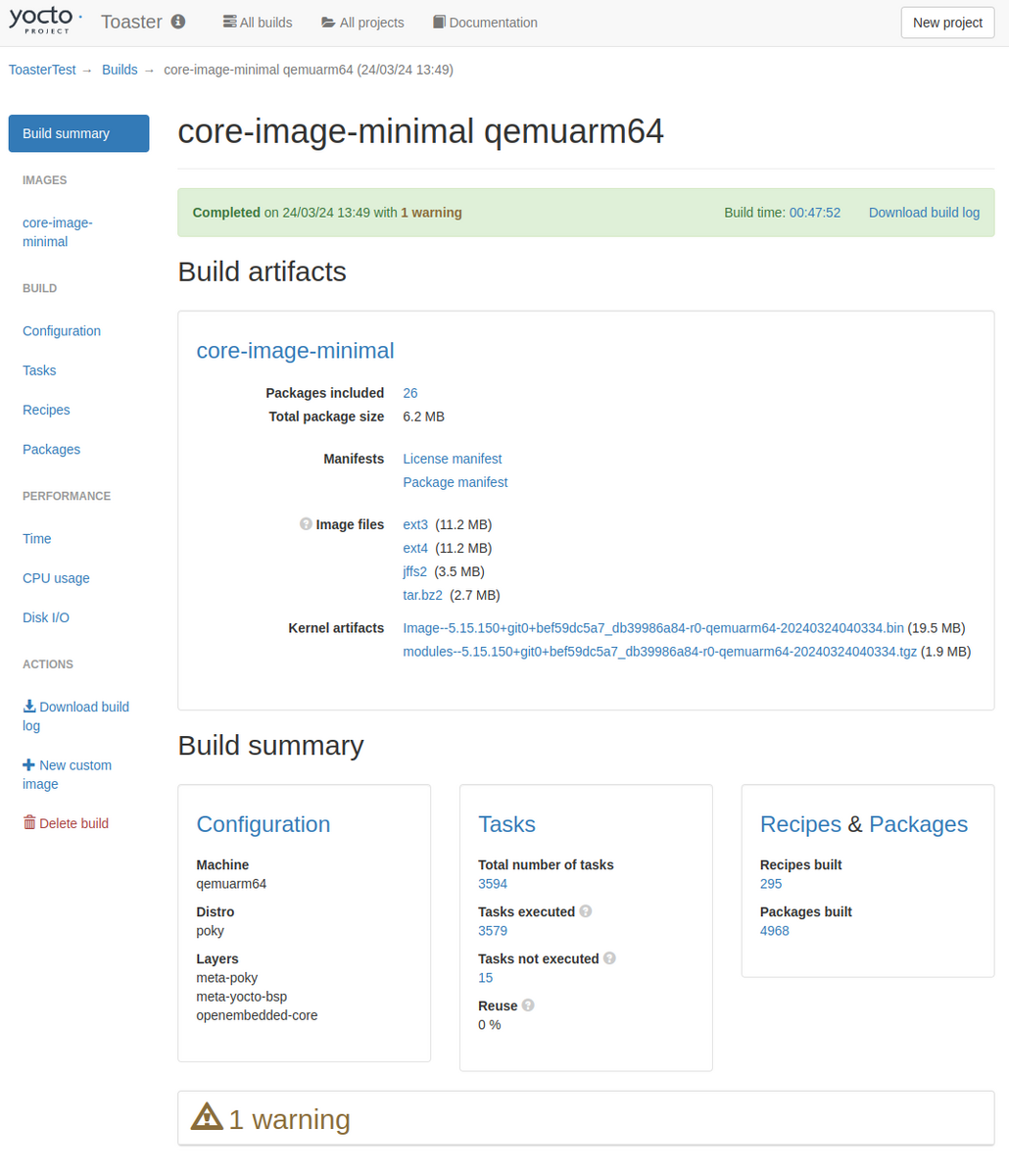
ビルド結果のファイルもここからダウンロードできる。
ビルドホストの状態
Toasterが実際に動作しているビルドホストはどのようになっているか確認する。
$ tree . -d -L 1
.
├── _toaster_clones
├── build
├── build-toaster-2
├── downloads
├── poky
└── sstate-cache
それぞれについては下記のようになっている。
| ディレクトリ |
概要 |
| _toaster_clones |
Toasterがダウンロードしたレイヤ |
| build |
最初のbuildディレクトリ |
| build-toaster-2 |
Toasterが作成したbuildディレクトリ |
| downloads |
ダウンロードキャッシュ |
| poky |
Poky |
| sstate-cache |
SStateキャッシュ |
ToasterはLayerIndexと連携して自動的にレイヤをダウンロードしたりする都合上、
自分が使用するレイヤは_toaster_clonesに格納するようになっている。
またビルドディレクトリは「build-toaster-n」の名前で管理される。
nの部分はToaster内のプロジェクト番号に紐づく。
今回作成したプロジェクト「ToasterTest」のプロジェクトのURLは「http://"IPアドレス":8400/toastergui/project/2/ 」になっていることから
プロジェクト番号は2であることがわかる。なのでビルドディレクトリも「build-toaster-2」となっている。
つまりToasterのプロジェクトとビルドディレクトリは1:1で紐付いていることになる。
Toasterで作成したプロジェクトのlocal.conf(toaster.conf)では、DL_DIRとSSTATE_DIRがあえてビルドディレクトリの1個上に設定されている。
これはプロジェクト間でダウンロードキャッシュとSStateキャッシュを共有しストレージや実行時間を短縮する狙いがあると推測できる。
ビルドディレクトリは下記のようになっている。
./build-toaster-2
├── buildhistory
├── cache
├── conf
└── tmp
一見普通のビルドディレクトリと変わらない。
confディレクトリを見ると違いがあることがわかる。
./build-toaster-2/conf/
├── bblayers.conf
├── local.conf
├── templateconf.cfg
├── toaster-bblayers.conf
└── toaster.conf
通常のlocal.confやbblayers.confの他にtoaster.confとtoaster-bblayers.confが存在している。
local.confのMACHINE設定を確認するとqemux86-64になっている。
$ grep 'MACHINE' ./build-toaster-2/conf/local.conf
#MACHINE ?= "qemuarm"
#MACHINE ?= "qemuarm64"
#MACHINE ?= "qemumips"
#MACHINE ?= "qemumips64"
#MACHINE ?= "qemuppc"
#MACHINE ?= "qemux86"
#MACHINE ?= "qemux86-64"
#MACHINE ?= "beaglebone-yocto"
#MACHINE ?= "genericx86"
#MACHINE ?= "genericx86-64"
#MACHINE ?= "edgerouter"
MACHINE ??= "qemux86-64"
#SDKMACHINE ?= "i686"
toaster.confのMACHINE設定を確認するとqemuarm64になっている。
$ grep 'MACHINE' ./build-toaster-2/conf/toaster.conf
MACHINE="qemuarm64"
このことからlocal.confは使用されずtoaster.confが使用されていることがわかる。
bblayers.confの内容は下記。
# POKY_BBLAYERS_CONF_VERSION is increased each time build/conf/bblayers.conf
# changes incompatibly
POKY_BBLAYERS_CONF_VERSION = "2"
BBPATH = "${TOPDIR}"
BBFILES ?= ""
BBLAYERS ?= " \
/home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta \
/home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-poky \
/home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-yocto-bsp \
"
toaster-bblayers.confの内容は下記。
# line added by toaster build control
BBLAYERS = "/home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta /home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-poky /home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-yocto-bsp"
現状ではToasterでレイヤの追加は行っていないのでどちらが使われているか判断できない。(がおそらくtoaster-bblayers.conf)
LayerIndexとの連携を試す
meta-oeなどのレイヤに含まれるレシピをビルドしてみる。
今回は適当にemacsを試す。
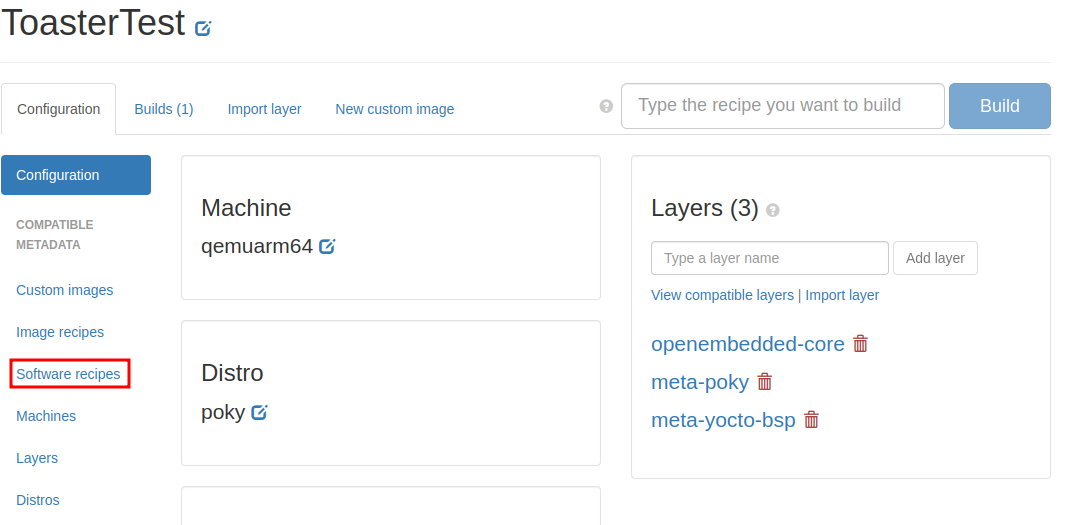
画面左側の「Software recipes」をクリック。
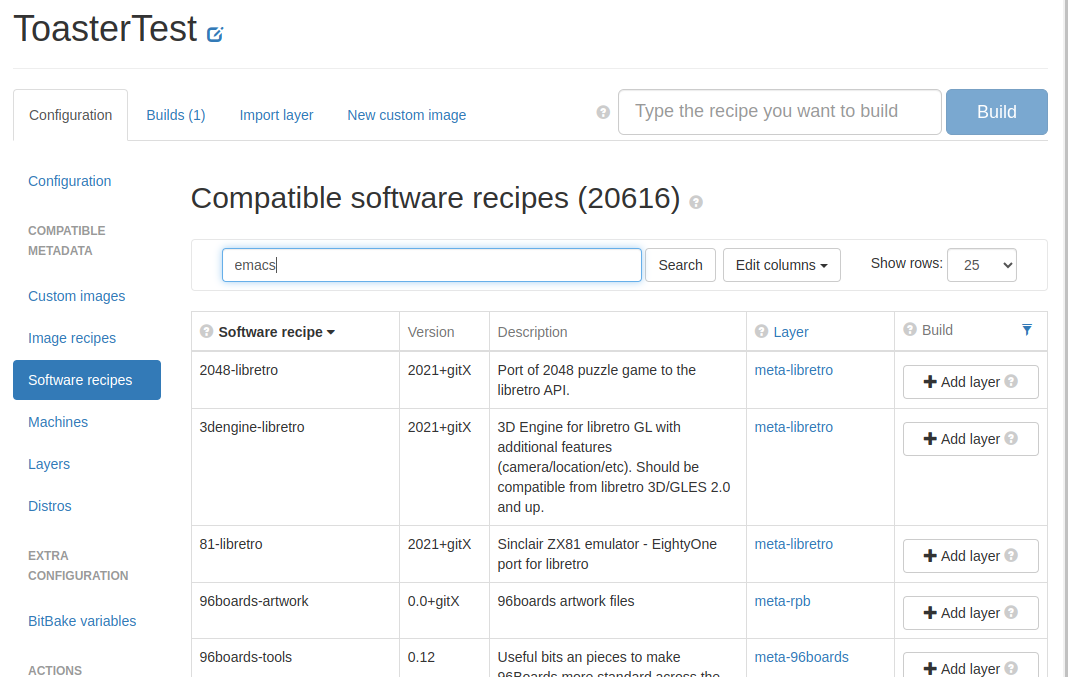
エディットにemacsと入力し、「Search」をクリック。
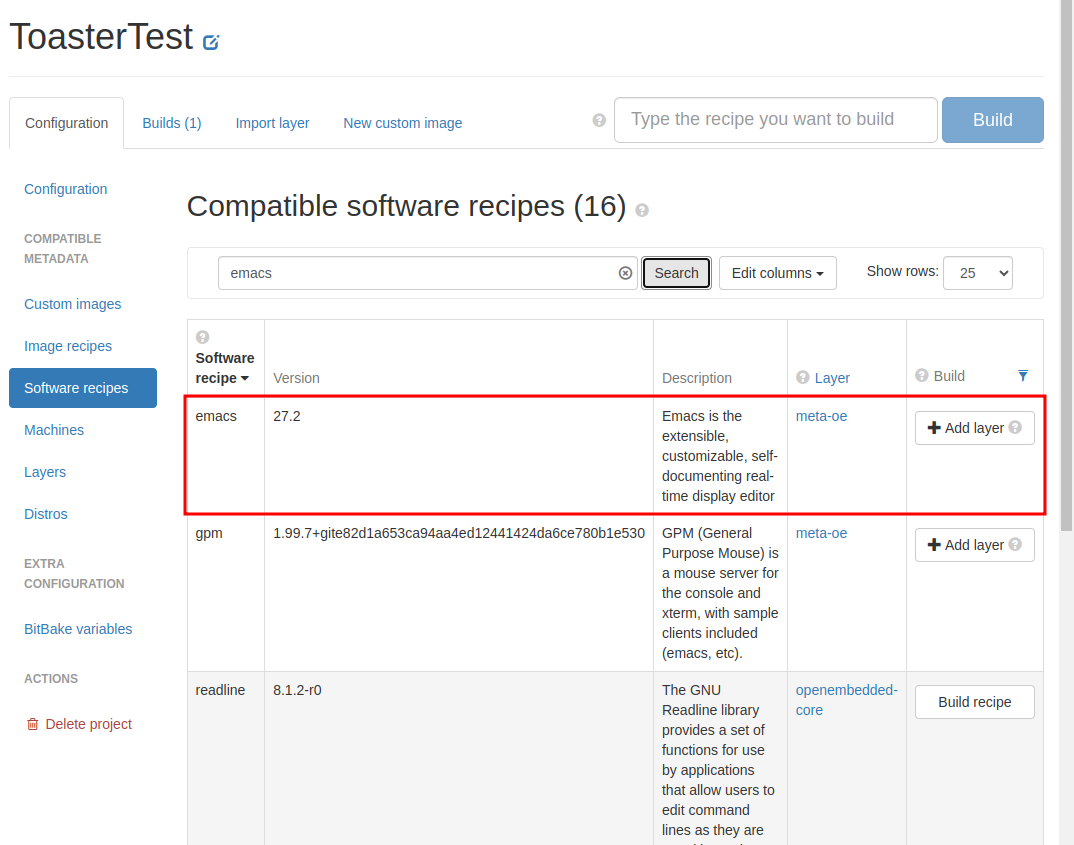
検索結果にemacsが現れるが、meta-oeはプロジェクトのビルド対象外なので「Add layer」が表示されている。
とりあえず「Add layer」をクリックする。
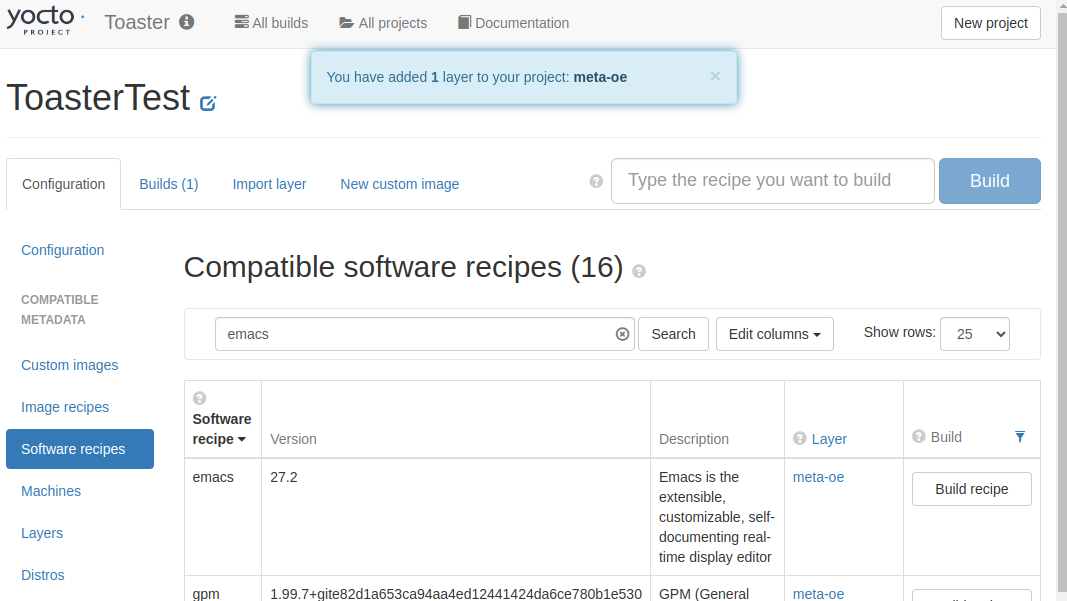
meta-oeがプロジェクトに追加され、「Build recipe」が表示された。
「Build recipe」をクリックしてビルドしてみる。
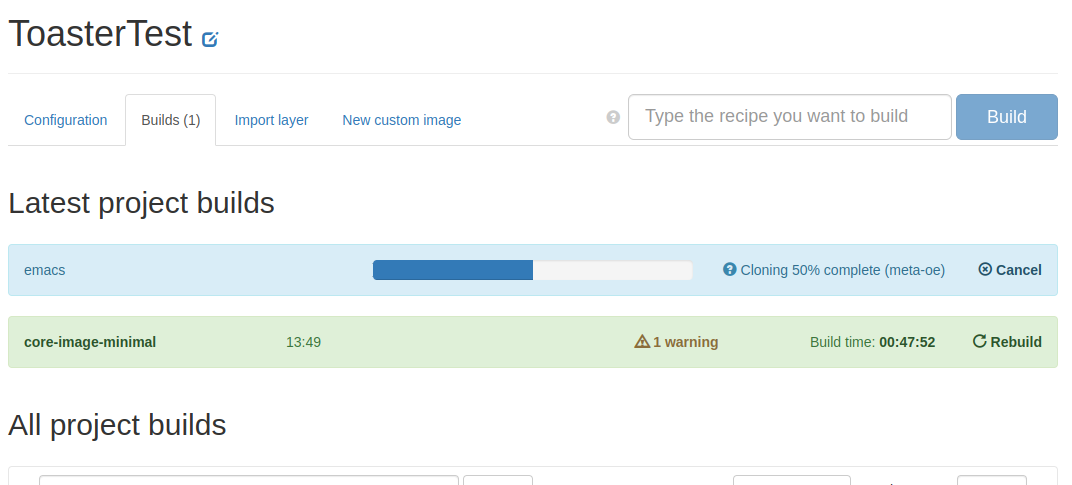
ビルドの進捗が表示される。
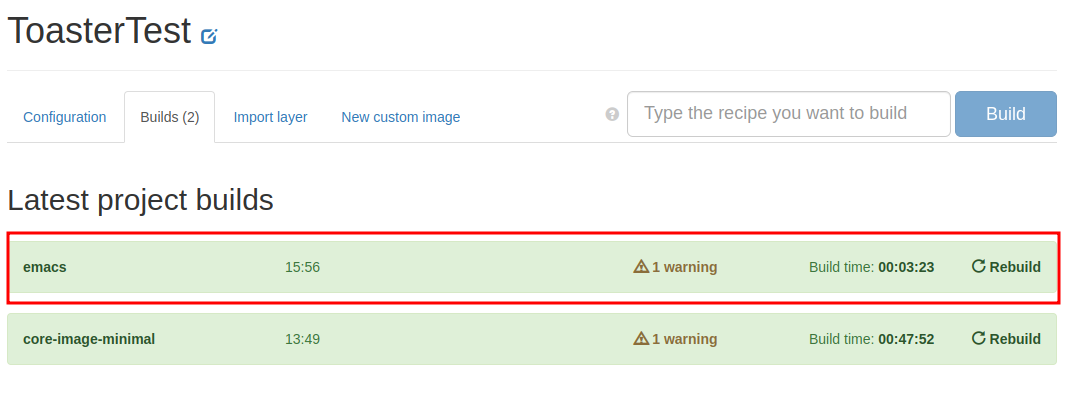
emacsのビルドが完了した。
LayerIndexに登録されているレシピをToasterの中だけで簡単に検索でき、プロジェクトへ追加できるのは便利かもしれない。
レイヤ追加後のビルドホストの状態
bblayers.confとtoaster-bblayers.confのどちらにmeta-oeが追加されているか確認する。
$ grep 'meta-oe' build-toaster-2/conf/bblayers.conf
$ grep 'meta-oe' build-toaster-2/conf/toaster-bblayers.conf
BBLAYERS = "/home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta /home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-poky /home/mickey/yocto/toaster/_toaster_clones/_git___git.yoctoproject.org_poky_kirkstone/meta-yocto-bsp /home/mickey/yocto/toaster/_toaster_clones/_git___git.openembedded.org_meta-openembedded_kirkstone/meta-oe"
Toasterからはtoaster-bblayers.confが使用されていることがわかった。
Command line buildsについて
ビルドホストでは、Toasterを起動するために読み込んだoe-init-build-envで作成されたビルドディレクトリであるbuildでbitbake可能な状態となっている。
Toasterを起動した状態でコマンドラインでビルドすると、ToasterからはCommand line buildsという特殊なプロジェクトとして扱われることになっている。
つまり、Toasterを起動した端末でbitbakeを行うこともできるようになっており、そのビルド時の情報もToasterでモニタリングできる。
試しに下記を実行してみる。
その前にToasterのダウンロードキャッシュとSStateキャッシュを参照するようにbuild/conf/local.confに下記を追加する。
DL_DIR = "${TOPDIR}/../downloads"
SSTATE_DIR = "${TOPDIR}/../sstate-cache"
bitbakeを実行する。
$ bitbake core-image-minimal
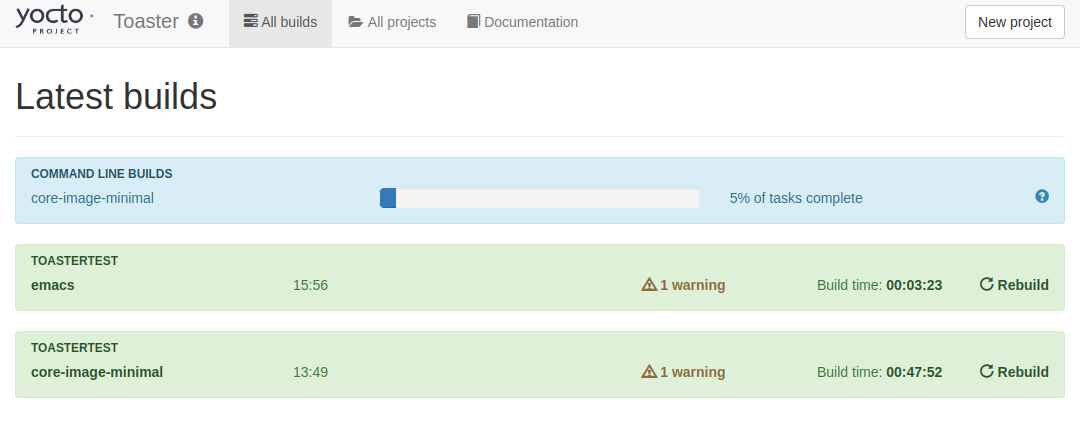
するとこのようにToaster上の「All builds」のタブで進捗が表示される。
その代わり、端末上の表示はいつものbitbakeの表示にはならない。
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/x86_64-linux/e2fsprogs-native/1.46.5-r0/temp/log.do_unpack.3681697
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/sqlite3/3_3.38.5-r0/temp/log.do_patch.3684828
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/util-macros/1_1.19.3-r0/temp/log.do_patch.3686898
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/libnsl2/2.0.0-r0/temp/log.do_deploy_source_date_epoch.3687362
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/xz/5.2.6-r0/temp/log.do_deploy_source_date_epoch.3686944
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/readline/8.1.2-r0/temp/log.do_deploy_source_date_epoch.3686976
NOTE: Logfile for task /home/mickey/yocto/toaster/build/tmp/work/core2-64-poky-linux/sqlite3/3_3.38.5-r0/temp/log.do_deploy_source_date_epoch.3687798
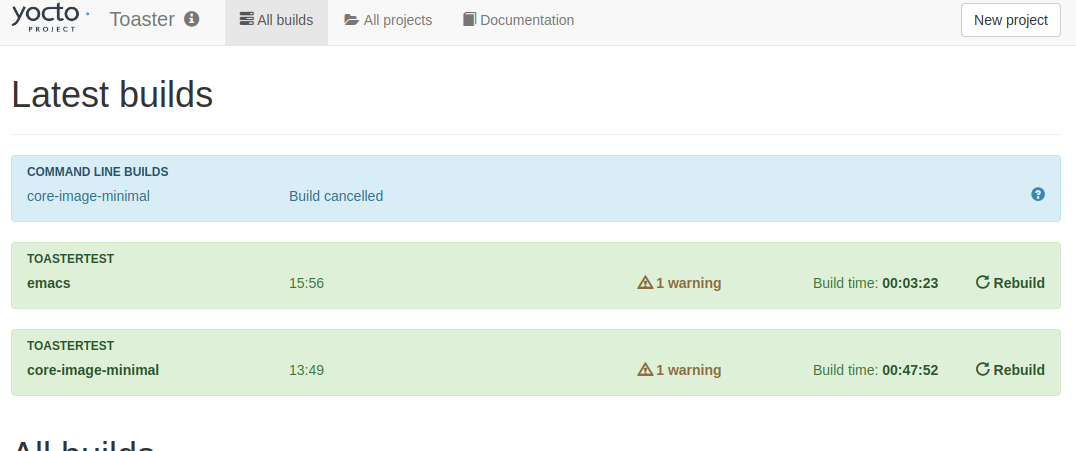
bitbakeをCtrl+Cで中断してもToasterはきちんと検出する。
再度実行し今度は最後まで走らせる。
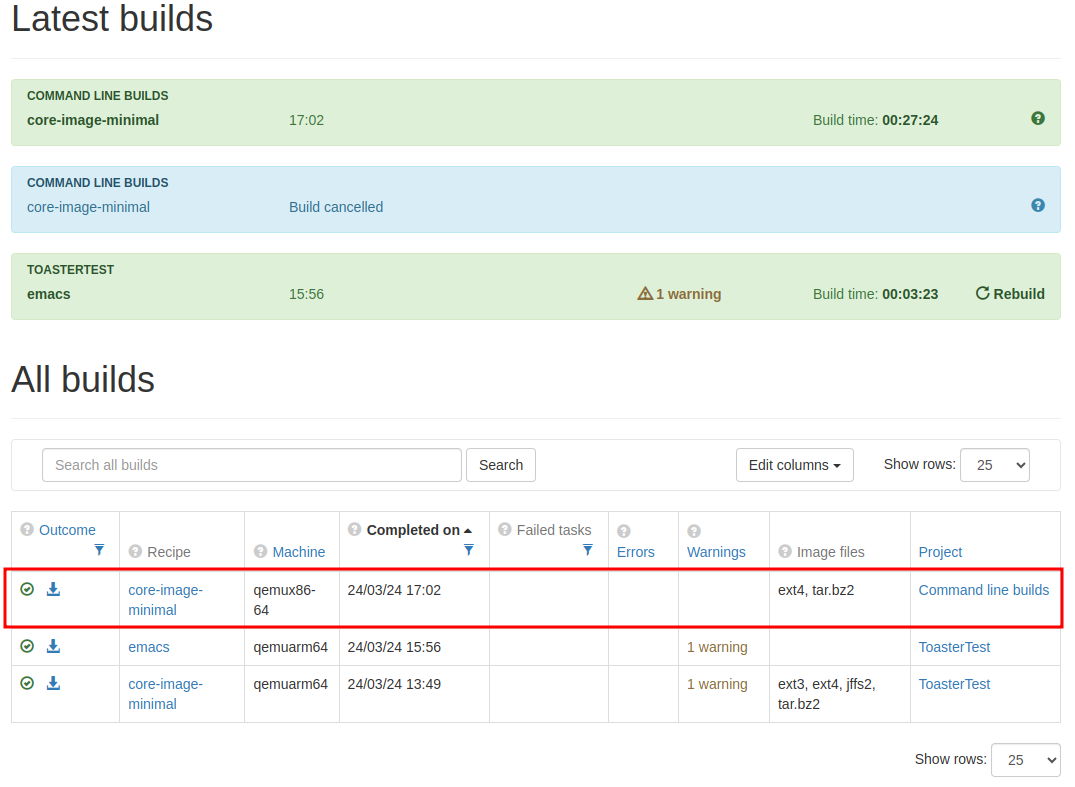
Projectが「Command line builds」になっている。
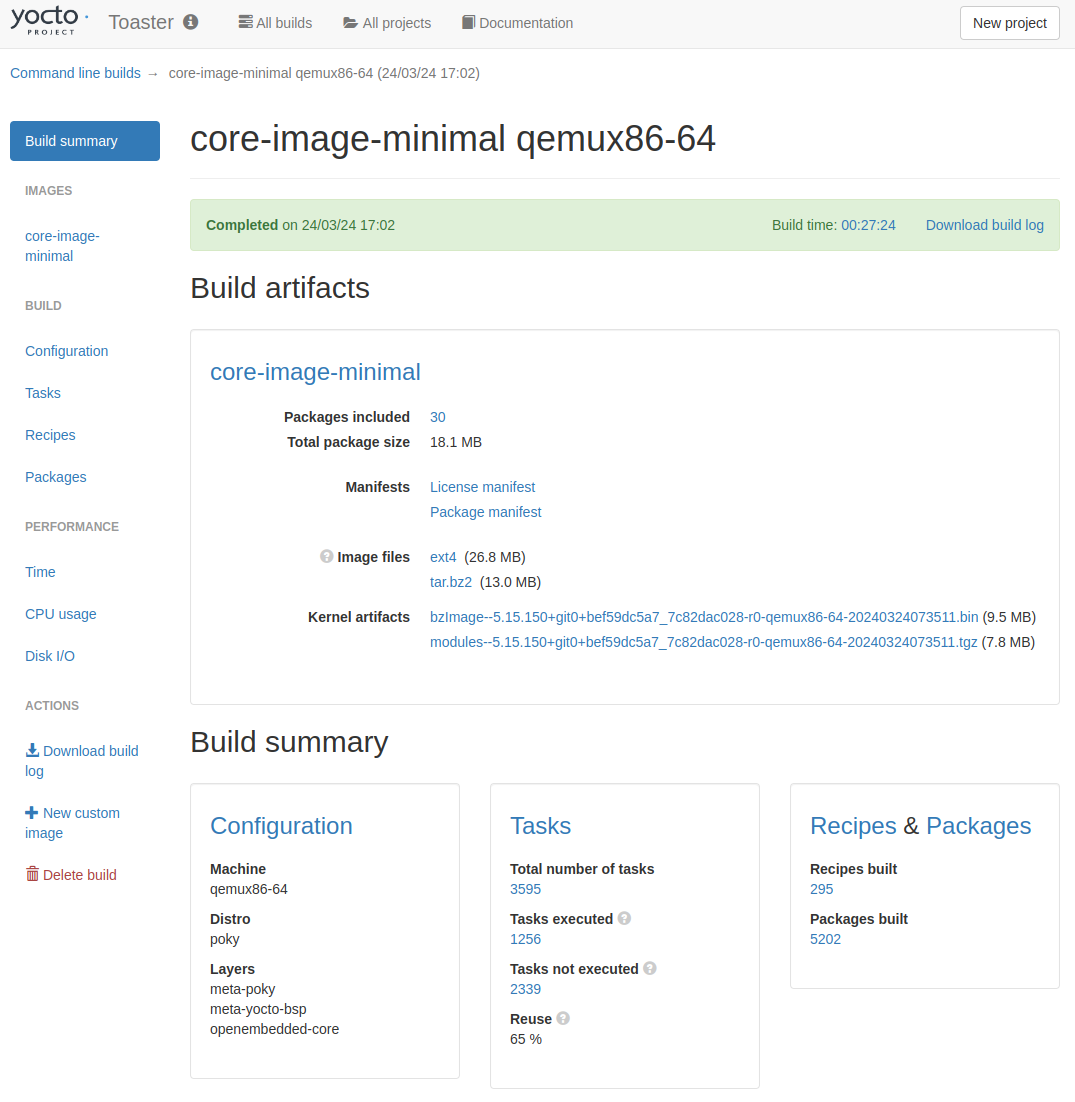
通常のToasterプロジェクトと同様にビルド結果を見ることができる。
既存のbitbake環境について
これまでToasterを使用せずに運用してきたbitbakeのビルドディレクトリについてもこの機能は使用することができる。
Toasterが起動した状態で1つでもタスクが実行されればToasterは情報収集を行うようだ。
なので、下記のようにすると既存の環境でもToasterの解析情報を使用することができる。
すでにcore-image-minimalがビルドされていると仮定して。
$ bitbake core-image-minimal -c clean
$ source toaster start nobuild webport=0.0.0.0:8400
$ bitbake core-image-minimal
nobuildオプションではToasterのプロジェクト作成およびビルド機能を無効にした状態で起動することができる。
Command line buildsの情報収集をするためだけならプロジェクト作成もビルド機能も不要なのでこのようにするとブラウザ上の操作もシンプルになる。
Toasterの終了
下記のコマンドでToasterを終了する。
$ source toaster stop
Toasterの気になる点
Toasterの3.10.2 Additional Information About the Local Yocto Project Releaseによると
Toaster will fetch the tip of your selected release from the upstream Yocto Project repository every time you run a build.
どういうことかというと、プロジェクト作成時に選んだYoctoProjectのRelease(バージョン)が対応するブランチが更新されると、Toasterでビルドを実行するたびにビルド環境にも反映されるということ。
これはビルド環境を更新していないけど、アップストリームのブランチに更新があるとToasterが自動的にそれを取り込むということになる。
組み込み開発環境では再現性を重視することが多いためバージョンやリビジョンを固定することが多い。
このような部分が自動的に行われるということはUncontrollableであるということにほかならない。
上記のリンクではこれを回避するためにはプロジェクト作成時に「Local Yocto Project」を選択とよいとなっているが、
その代わり「Local Yocto Project」ではLayerIndexとの連携は行わないとなっている。
それではあまりToasterを使うメリットもないように思う。
まとめ
- YoctoProjectはToasterというWebインターフェースを提供している
- 主な目的はコマンドラインに不慣れなユーザー向けらしい(がオフィシャルなマニュアルにはToasterのメリットや目的の記載が見つからない)
- ToasterはLayerIndex(主にOpenEmbedded Layer Index)と連携している
- ビルド時の情報をsqliteのDBに保存している
- コマンドラインのbitbakeのビルド情報を収集することができる
- ビルドごとにレイヤをフェッチし直すらしい
結局色々とやってみたが、筆者の感想としてはコマンドラインのbitbakeの情報収集以外に便利そうな要素が無い。
ポーティングやBSPの開発ではToasterを使用するにはオーバーヘッドが大きすぎる。
毎回レイヤをフェッチし直すというリスクもある。
例えばアップストリームでカーネルのレシピが更新されれば運が悪ければ変更中のドライバのパッチが急に当たらなくなる可能性もある。
(もちろんBug Fix、Security Fixがメインなので確率は低いと思うが。。。)
Local Yocto Projectを使用すればフェッチのリスクは回避できるが、LayerIndexとの連携がなくなるのでそもそも使う理由がなくなる気がする。
機能紹介やチュートリアルはよく見かけるのだが、想定するUseCaseがいまいちわからない。Toasterのマニュアルにもそういう記載は見つけられなかった。特にCI的に使用もしくは連携できるわけでもなさそうだし。
想定するユーザー層をもう少し明確にしてもらえると嬉しいかもしれない。
2024/5/2 追記
Toasterをブラウザで開くPCがWindowsマシンだったら嬉しいのかもしれない。